如何实现高吞吐的定时任务处理
如何实现高吞吐的定时任务处理
实现一个定时任务的调度不算太难,一个简单的思路如下:一个存放定时任务的队列,一个按照固定时间间隔扫描的线程,这个线程每隔一段时间扫描队列里的所有任务,如果需要执行就进行调度。
首先,这个任务一定要暴露一些属性,使得线程可以判断某个时刻是否需要执行:
1 | |
其次,这个线程里需要存储所有添加进来的任务,并每隔一段时间扫描任务是否需要执行:
1 | |
分析一下上述代码都有什么问题:
- 任务队列 taskList 是一个简单的 ArrayList,多线程并发添加任务时可能出现线程安全问题;
- 在取出 task 后,直接在当前的线程里执行了 task 的 run 方法,如果耗时很长,会延迟后续任务的执行甚至影响到下次循环;
- 每个 durationMs 间隔周期,都需要遍历 taskList 中的所有任务,当任务很多时会耗时很长。
为了解决这些问题可以将 ArrayList 修改为线程安全的队列,这个队列最好还能按照某个顺序排列(例如按照预计执行时间,这样取出的第一个元素如果都不能满足执行条件,就无需向后遍历了)。
那么这个队列有什么选项呢?
ScheduledThreadPoolExecutor
JDK 的定时任务执行器 ScheduledThreadPoolExecutor 供了周期执行任务和延迟执行任务的特性:
1 | |
查看 ScheduledThreadPoolExecutor 的构造方法,其使用了 DelayedWorkQueue 作为任务队列:
1 | |
DelayedQueue 是 JDK 中一种可以延迟获取对象的阻塞队列,其内部是采用优先级队列 PriorityQueue 存储对象。DelayQueue 中的每个对象都必须实现 Delayed 接口,并重写 compareTo 和 getDelay 方法,在 自定义EventLoopGroup 中有过使用 。DelayQueue 提供了 put() 和 take() 的阻塞方法,可以向队列中添加对象和取出对象。对象被添加到 DelayQueue 后,会根据 compareTo() 方法进行优先级排序。getDelay() 方法用于计算消息延迟的剩余时间,只有 getDelay <=0 时,该对象才能从 DelayQueue 中取出。
DelayedQueue 依赖 PriorityQueue(优先级队列实现),是线程安全的,PriorityQueue 是一个小顶堆的结构,任务会根据 compareTo() 方法进行排序,所以队列的第一个元素一定是最先需要执行的(但是 PriorityQueue 只保证第一个元素是最先执行的,不保证整体有序)。
由于 DelayedQueue 每次插入任务时都需要重新排序,平均的时间复杂度 O(logN),在面对很多任务时会有明显的性能瓶颈。
那么一个支持大量延迟任务的数据结构该如何实现?
时间轮
如果想要在大量数据里迅速找到某个元素,哈希表是唯一的选择。
想象一下时钟的秒针,把 1 分钟分为 60 秒,时间轮也是类似的结构,举个例子:一个对象里有一个长度为 60 的数组,每个数组代表 1s,当我们拿到了一个定时任务,知道了它下次执行的时间 deadline(毫秒),那么 (deadline / 1000) % 60 就是这个任务需要放置的数组位置,数组使用链表法解决哈希冲突。
注意:上述只是为了举例,在计算机系统里,1s 可以做很多事情了,所以一个元素代表的时间一般要很小,而且数组长度通常设置为 2 的幂,方便位运算取模。
Hashed and Hierarchical Timing Wheels 这篇文章比较了实现定时器的各种数据结构,并提出了层次化的 timing wheel 和 hash timing wheel 等结构。
时间轮可以理解为一种环形结构,像钟表一样被分为多个 slot 槽位。每个 slot 代表一个时间段,每个 slot 中可以存放多个任务,使用的是链表结构保存该时间段到期的所有任务。时间轮通过一个时针随着时间一个个 slot 转动,并执行 slot 中的所有到期任务。
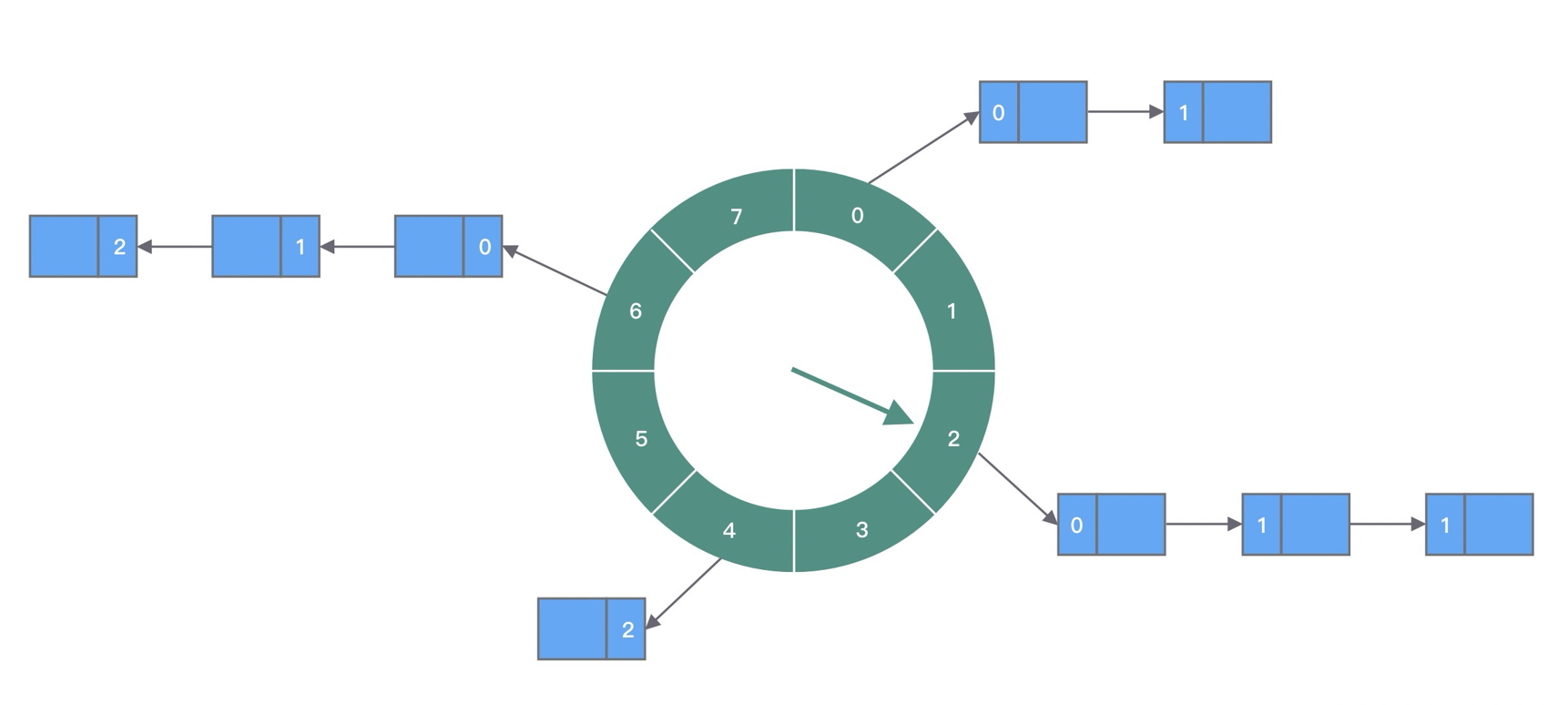
以上图为例,这个时间轮中有一个长度为 8 的数组,假设每个代表 1s,现在指针指向 2 的位置,如果需要添加一个 12s 后执行的任务,那么就需要放置到 ((2 + 12) / 1 % 8) 也就是 slot6 的位置。
当指针走到 slot6 时,怎么判断每个任务是现在就执行还是在后续的轮次中执行呢?第一种方式是遍历所有的任务,取任务的 deadline <= 对应时间(时间轮启动时间 + 转动次数 * 每次转动代表的周期)的任务,第二种方式在添加任务到 slot 时就计算会在第几轮执行,像现在添加一个 12s 后执行的任务对应的轮次就是 (2 + 12) / 8,也就是下一轮次执行,这样每一个 slot 只取轮次为 0 的任务执行即可,其他任务的轮次减去1。
时间轮有点类似 HashMap,如果多个任务如果对应同一个 slot,处理冲突的方法采用的是拉链法。在任务数量比较多的场景下,适当增加时间轮的 slot 数量,可以减少时针转动时遍历的任务个数。
时间轮通过牺牲任务精度的方式换来大量定时任务插入时 O(1) 的时间复杂度以及大量任务的尽可能及时执行。这句话该怎么理解呢?
- 插入时 O(1) 的时间复杂度:指的是通过取余的方式可以直接计算出新任务需要放置的位置;
- 大量任务的尽可能及时执行:指的是在由于任务被分配在不同的 slot,所以每次只需要遍历该 slot 的任务,对比需要遍历所有任务判断是否需要执行的数据结构来说,减少了由于遍历任务容器耗时导致在容器靠后位置的任务进一步推迟执行的可能(遍历的任务数少了,为之前的 1 / slot);
- 牺牲任务精度:这就是时间轮缺点了
- 假如两个任务分别在 1.2 和 1.3 秒后执行,二者落到了同一个 slot,甚至由于插入顺序的不同,1.3 秒的任务早于 1.2 秒的任务先被执行;
- 假如插入任务是头插法,此时时间轮线程已经遍历到了链表中间的位置,所以新插入的任务会延迟到下一轮执行,如果是图示中的结构,会延迟到 8 秒后执行,可以通过控制一个元素代表的时间来缩小这个周期。
Netty 的时间轮实现
HashedWheelTimer 是 Netty 中时间轮算法的实现类,有几个核心成员:
- HashedWheelTimeout,任务的封装类,包含任务的到期时间 deadline、需要经历的圈数 remainingRounds 等属性。
- HashedWheelBucket,相当于时间轮的每个 slot,内部采用双向链表保存了当前需要执行的 HashedWheelTimeout 列表。
- Worker,HashedWheelTimer 的核心工作引擎,负责处理定时任务。
来看一个 demo:
1 | |
输出如下:
1 | |
timeout2 和 timeout3 相差 5s,这其实是因为 timeout2 中 Thread.sleep(5000) 导致的,但是这反映出一个问题:HashedWheelTimer 默认是使用一个线程来执行时间轮的任务,当一个任务执行的时间过长,会影响后续任务的调度和执行,很可能产生任务堆积的情况。
Netty 自然也考虑到了这样的情况,提供了相应的构造方法来使用线程池处理 slot 中的任务,这样时间轮线程只负责指针的转动,即使业务逻辑执行缓慢,也不会拖慢时间轮的整体进度。
1 | |
对于时间轮来说,可能有多个线程同时向其中追加任务,同时时间轮线程也在扫描任务并移除放入到线程池中执行,这是一个典型的多生产者单消费者场景。Netty 并不会把任务直接添加到时间轮中,而是先放到一个 Mpsc Queue 队列里,借助 Mpsc Queue 保证多线程向时间轮添加任务的线程安全性。
另外 Netty 中的时间轮是通过固定的时间间隔 tickDuration 进行推动的,如果长时间没有到期任务,那么会存在时间轮空推进的现象,从而造成一定的性能损耗。
Kafka 的时间轮实现
Kafka 也有时间轮的应用,它的实现思路与 Netty 存在区别的,但数据结构部分类似,Kafka 的时间轮也是采用环形数组存储定时任务,数组中的每个 slot 代表一个 Bucket,每个 Bucket 保存了定时任务列表 TimerTaskList,TimerTaskList 同样采用双向链表的结构实现,链表的每个节点代表真正的定时任务 TimerTaskEntry。
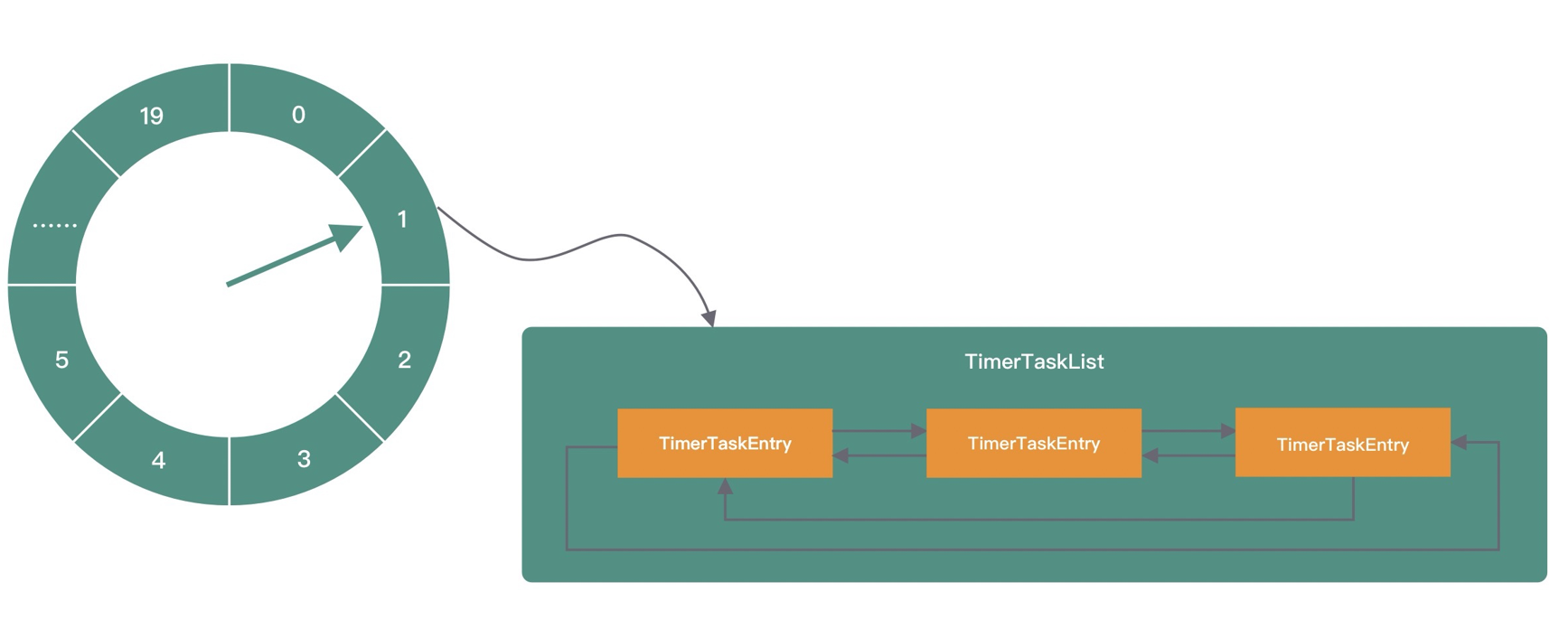
为了解决空推进的问题,Kafka 借助 JDK 的 DelayQueue 来负责推进时间轮。DelayQueue 保存了时间轮中的每个 Bucket,并且根据 Bucket 的到期时间进行排序,最近的到期时间被放在 DelayQueue 的队头。Kafka 中会有一个线程来读取 DelayQueue 中的任务列表,如果时间没有到,那么 DelayQueue 会一直处于阻塞状态,从而解决空推进的问题。DelayQueue 只存放了 Bucket,Bucket 的数量并不多,相比空推进带来的影响是利大于弊的。
Kafka 还使用了多级时间轮来处理时间跨度过大的问题:
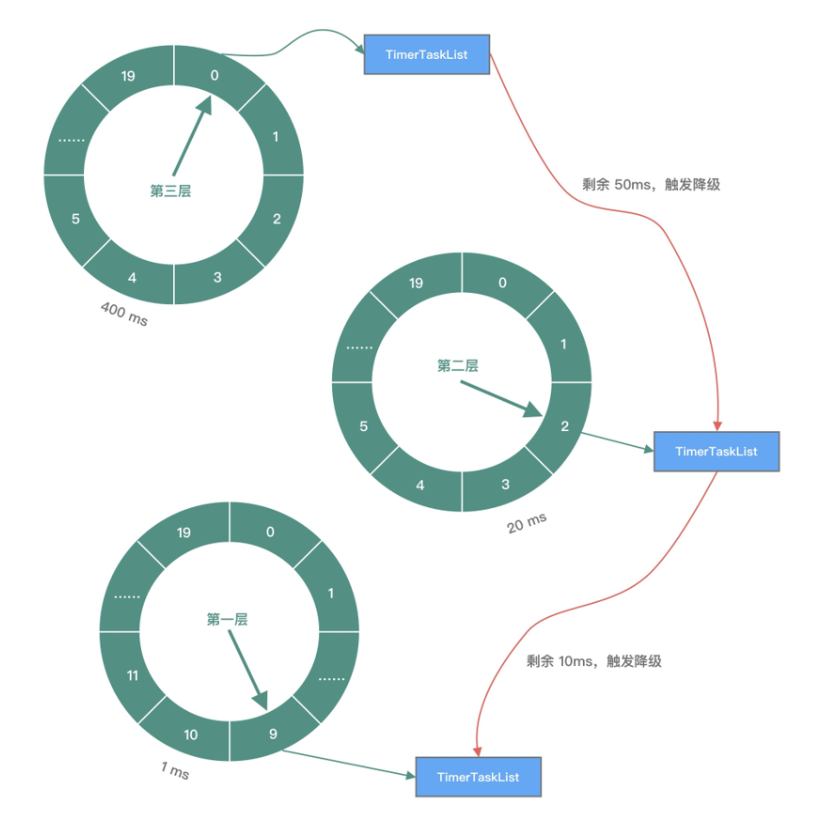
从图中可以看出,第一层时间轮每个时间格为 1ms,整个时间轮的跨度为 20ms;第二层时间轮每个时间格为 20ms,整个时间轮跨度为 400ms;第三层时间轮每个时间格为 400ms,整个时间轮跨度为 8000ms。每一层时间轮都有自己的指针,每层时间轮走完一圈后,上层时间轮也会相应推进一格。
假设现在有一个任务到期时间是 450ms 之后,应该放在第三层时间轮的第一格。随着时间的流逝,当指针指向该时间格时,发现任务到期时间还有 50ms,这里就涉及时间轮降级的操作,它会将任务重新提交到时间轮中。此时发现第一层时间轮整体跨度不够,需要放在第二层时间轮中第三格。当时间再经历 40ms 之后,该任务又会触发一次降级操作,放入到第一层时间轮,最后等到 10ms 后执行任务。
层级时间轮对时间粒度进行了更好的控制,可以应对更加复杂的定时任务处理场景,适用的范围更广。
小结
本文从基础定时任务实现的缺陷切入,逐步剖析了高吞吐定时任务的演进方案,对比了 JDK、Netty、Kafka 三种经典实现,梳理了定时任务调度的优化思路与核心原理:
- 基础定时方案的瓶颈:简单队列 + 轮询扫描的实现,存在线程不安全、任务执行阻塞轮询、全量遍历耗时三大问题,无法支撑大量定时任务场景;JDK 的
ScheduledThreadPoolExecutor基于优先级队列解决了排序和线程安全问题,但插入任务复杂度为O(logN),高并发下性能瓶颈明显。 - 时间轮算法核心优势:借鉴时钟环形结构,通过哈希取模的思想定位任务槽位,任务插入复杂度为O(1),仅需遍历当前槽位任务,大幅提升吞吐;以牺牲任务执行精度为代价,实现了大量定时任务的高效调度,是高吞吐场景的最优解。
- 主流框架时间轮实现差异
- Netty HashedWheelTimer:单时间轮设计,采用 MPSC 队列 保证多线程安全,默认单线程执行任务易阻塞,支持自定义线程池解耦调度与执行,存在空推进损耗;
- Kafka 时间轮:基于 DelayQueue 解决空推进问题,仅在任务到期时唤醒线程,同时采用多级时间轮适配超大时间跨度的定时任务,通过层级降级实现精准调度,适用性更广。
整体而言,时间轮是解决海量、高吞吐定时任务的核心方案,Netty 与 Kafka 的实现分别适配了轻量调度、大规模分布式调度的不同场景。