Netty的Mpsc队列如何实现
Netty的Mpsc队列如何实现
队列是一种 FIFO(先进先出)的数据结构,JDK 中定义了 java.util.Queue 的队列接口,与 List、Set 接口类似,java.util.Queue 也继承于 Collection 集合接口。此外,JDK 还提供了一种双端队列接口 java.util.Deque,我们最常用的 LinkedList 就是实现了 Deque 接口。JDK 提供了一些并发队列如:ArrayBlockingQueue、ConcurrentLinkedQueue,但是在大规模流量的高并发系统中,如果对性能要求严苛,JDK 的并发队列性能并不够出色。
高并发情况下使用的数据结构通常希望是非阻塞的,Netty 采用了开源项目 JCTools 的并发数据结构,其中非阻塞队列可以分为四种类型,可以根据不同的场景选择使用。
- Spsc 单生产者单消费者;
- Mpsc 多生产者单消费者;
- Spmc 单生产者多消费者;
- Mpmc 多生产者多消费者。
伪共享
在 性能优化之CPU篇 中,有介绍多核 CPU 的结构。程序在执行时,会先将内存中的数据载入三级缓存,再进入每颗核心独有的二级缓存,最后进入最快的一级缓存,之后才会被 CPU 使用。
伪共享的场景就与CPU的多核架构有关:
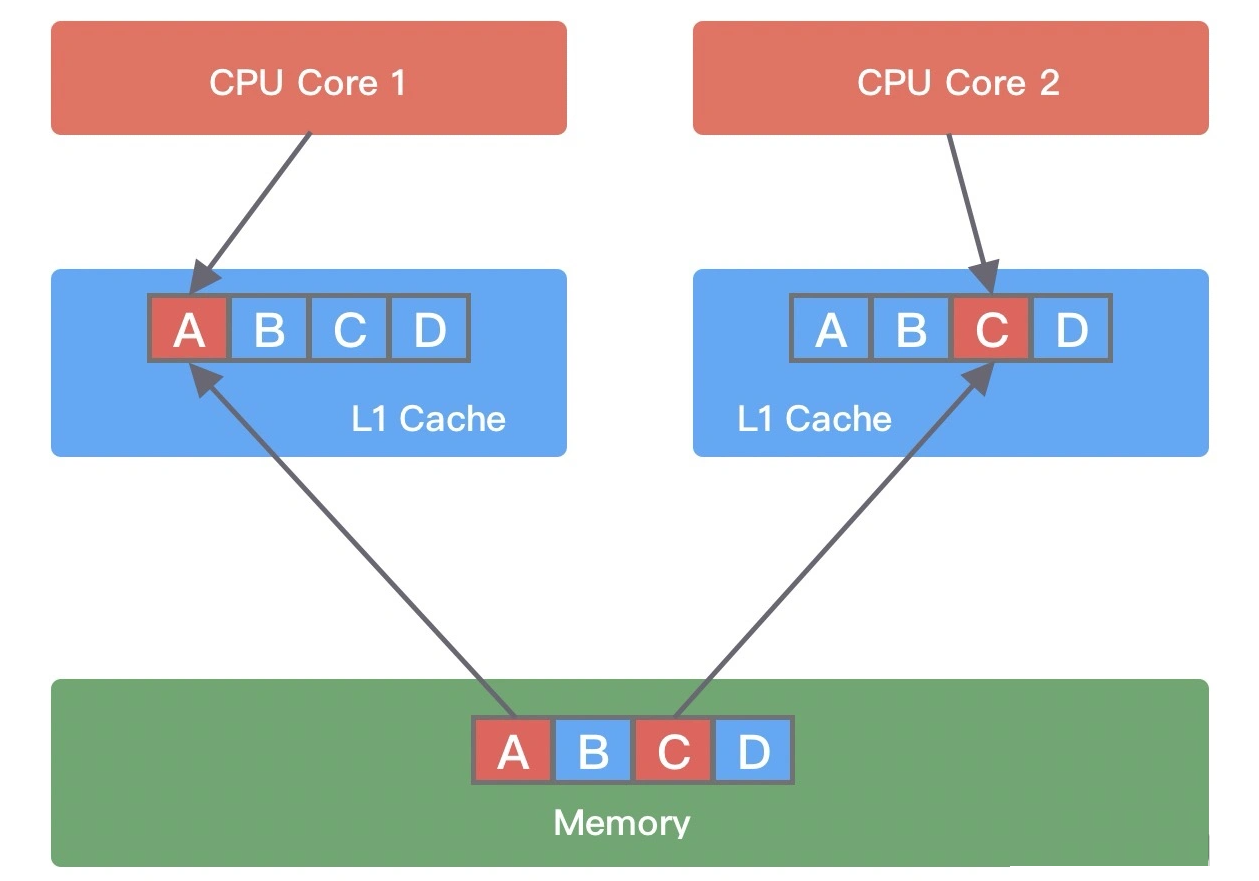
假设变量 A、B、C、D 被加载到同一个 Cache Line,它们会被高频地修改。当线程 1 在 CPU Core1 中中对变量 A 进行修改,修改完成后 CPU Core1 会通知其他 CPU Core 该缓存行已经失效。然后线程 2 在 CPU Core2 中对变量 C 进行修改时,发现 Cache line 已经失效,此时 CPU Core1 会将数据重新写回内存,CPU Core2 再从内存中读取数据加载到当前 Cache line 中。
所以同一个 Cache line 被越多的线程修改,那么造成的写竞争就会越激烈,数据会频繁写入内存,导致性能浪费。
解决伪共享问题的方式就是让变量处于不同的 cache line 上。假如这是个 long 变量占 8B,cache line 大小通常是 64B,在这个变量的前后各填充 7 个 long 类型的变量,就可以让不同线程共享的对象加载到不同的缓存行。
Mpsc Queue 为了解决伪共享问题填充了大量的 long 类型变量,这也导致源码不易阅读。伪共享问题一般是非常隐蔽的,在实际开发的过程中,并不是项目中所有地方都需要花费大量的精力去优化伪共享问题,因为 CPU Cache 的填充本身也是比较珍贵的。
入队与出队
JCTools 提供了 MpscArrayQuene、MpscUnboundedArrayQueue、MpscChunkedArrayQueue 多个具有特色功能的队列,这里分析比较简单的 MpscArrayQuene。
源代码中 MpscArrayQuene 连续继承了很多类,所以这些核心属性也分布在很多类中,整理如下:
1 | |
读过 redis 或者一些哈希表源码的人一眼就觉得 mask 就是数组的长度 - 1,原因是在哈希表获取元素所在位置时,取模运算需要重复计算,而 & 位运算只需要一次, (% 2^n) 和 (& 2^n -1) 结果是一样的。
producerIndex、producerLimit 都是用 volatile 进行修饰的,因为一个生产者线程的修改需要对其他生产者线程可见。
队列的核心操作就是入队和出队。
offer
offer(E e) 的作用是将元素加入队列,满了则返回 false,成功则返回 true。
这里有几个重要变量:
- mask 数组长度-1
- producerLimit 缓存的生产者索引上限(如果不缓存,每次都要读取 consumerIndex 来判断队列是否已满,而 consumerIndex 需要 volatile 去读,频繁跨缓存行读取会降低性能)
1 | |
在 do-while 循环内的逻辑,需要两次 if(pIndex >= producerLimit) 判断,因为当生产者索引大于 producerLimit 阈值时,可能存在两种情况:producerLimit 缓存值过期了或者队列已经满了
- 读取最新的消费者索引 consumerIndex,之前读取过的数据位置都可以被重复使用,重新做一次 producerLimit 计算;
- 然后再做一次 if(pIndex >= producerLimit) 判断,如果生产者索引还是大于 producerLimit 阈值,说明队列的真的满了。
在最后向数组指定位置放数据时的 soElement 的实现如下:
1 | |
putOrderedObject() 和 putObject() 都可以用于更新对象的值,但是 putOrderedObject() 并不会立刻将数据更新到内存中,并把其他 Cache Line 置为失效。putOrderedObject() 使用的是 LazySet 延迟更新机制,所以性能方面 putOrderedObject() 要比 putObject() 高很多。
其实这是一个环形数据,长度是2的幂次方,calcElementOffset(pIndex, mask)就是计算本次该写在数组的哪个位置。
poll
poll() 方法的作用是移除队列的首个元素并返回,如果队列为空则返回 NULL。
1 | |
因为只有一个消费者线程,所以 poll() 的过程没有 CAS 操作。poll() 方法核心思路是获取消费者索引 consumerIndex,然后根据 consumerIndex 计算得出数组对应的偏移量,然后将数组对应位置的元素取出并返回,最后将 consumerIndex 移动到环形数组下一个位置。
lvElement 取出数组中 offset 对应的元素使用了 UNSAFE 系列方法,getObjectVolatile() 方法使用的是 LoadLoad Barrier(对于 Load1,LoadLoad,Load2 操作序列,在 Load2 以及后续读取操作之前,会保证 Load1 的读取操作执行完毕),所以 getObjectVolatile() 方法可以保证每次读取数据都可以从内存中拿到最新值。
1 | |
与 offer() 不同,poll() 比较关注队列为空的情况。当调用 lvElement() 方法获取到的元素为 NULL 时,有两种可能的情况:队列为空或者生产者填充的元素还没有对消费者可见。如果消费者索引 consumerIndex 等于生产者 producerIndex,说明队列为空。只要两者不相等,消费者需要等待生产者填充数据完毕。
小结
MpscArrayQueue 中蕴藏着丰富的技术细节:
- 通过大量填充 long 类型变量解决伪共享问题;
- 环形数组的容量设置为 2 的次幂,可以通过位运算快速定位到数组对应下标;
- 入队 offer() 操作中 producerLimit 的巧妙设计,大幅度减少了主动获取消费者索引 consumerIndex 的次数,性能提升显著;
- 入队和出队操作中都大量使用了 UNSAFE 系列方法,针对生产者和消费者的场景不同,使用的 UNSAFE 方法也是不一样的。
在 Netty 的 EventLoop 模型中,多个 Channel 可能会同时触发可读事件,然后 EventLoop 将事件派发给业务线程池去执行业务操作,业务线程处理完业务逻辑后,可能并发调用EventLoop提交任务的方法,提交写数据的IO任务,这些任务会添加到 EventLoop 的任务队列中。而 EventLoop 本质上是一个单线程的执行器,它会从任务队列中取出任务并执行。
这个场景完美契合 Mpsc(Multi Producer Single Consumer)模型。