设计模式中的经典设计原则 设计模式中有一些经典的设计原则,包括:SOLID、KISS、YAGNI、DRY、LOD 等。
其中 SOLID 分别对应 单一职责原则、开闭原则、里式替换原则、接口隔离原则 和 依赖反转原则。
单一职责原则 Single Responsibility Principle:A class or module should have a single reponsibility,翻译过来就是 一个类或者模块只负责完成一个职责。
我曾经实习的公司关于 code review 就有一些规定:代码参数不能超过 5 个,函数行数不能超过 100 行,否则认为函数的功能不够单一,其实我觉得行数这个事情应该分情况,所有的错误信息都应该打印出来或者至少不能丢失,而 go 语言当时又经常出现下面的情况:
1 2 3 4 if err != nil {error ("..... failed:%v" , err);return nil , err;
导致代码行数经常介于边缘。这个原则的判断需要根据具体情况来分析,例如有一个 UserInfo 的类,类中主要属性为用户信息和地址信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class UserInfo {private long userId;private String username;private String email;private String telephone;private long createTime;private long lastLoginTime;private String avatarUrl;private String provinceOfAddress; private String cityOfAddress; private String regionOfAddress; private String detailedAddress;
可以看到地址信息在 UserInfo 中的比重是很高的,可以拆分出来单独维护 Address 类,结合具体情况分析:
这是一个社交软件,用户信息就是有所在地省市区,如果拆分出来查询的时候反而需要再聚合,这时就可以不再拆分;
这是一个购物软件,address 可能有多个,用来选择收货地址,那么久可以拆分出来维护地址信息。
因此在不同的应用场景,不同的发展阶段,对同一个类的职责是否单一的判定是有可能不一样的。在实际开发过程中,可以先写一个粗粒度的类,满足业务需求,随着业务的发展再进行持续的重构。
但是依然有一些原则可以用来指导判断类是否职责单一:
参数、行数或属性过多;
类依赖的其他类过多;
私有方法过多;
类、函数已经很难起新的命名了;
类中大量的方法都是在操作其中的几个属性。
单一职责原则希望避免设计大而全的类而导致功能耦合,以提高类的内聚性;同时,类职责单一,依赖和被依赖的其他类变少,也可以减少代码的耦合性。
开闭原则 Open Closed Principle:software entities (modules, classes, functions, etc.) should be open for extension , but closed for modification。翻译一下就是:软件实体(模块、类、方法等)应该“对扩展开放、对修改关闭”。
例如要实现一个拦截器的功能,用户分为两类,普通用户和管理用户
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public boolean preHandle (HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {if (handler.getClass().isAssignableFrom(HandlerMethod.class)) {if (isExclusion(handler)) {return true ;String token = request.getHeader("Authorization" );if (StringUtils.isBlank(token)) {"access_token" );if (StringUtils.isBlank(token)) {return false ;UserToken userFromToken = tokenService.getUserFromToken(token);if (tokenTimeOut(token, userFromToken, request)) {return false ;return true ;
目前的规则是很简单的,只是单纯的判断 token 是否过期,随着时间的推移慢慢有了更多的需求……
/admin/* 下的所有请求只有管理用户能访问;
新增截止日期,在截止日期之后只有管理用户能访问;
如果用户状态是……那么只允许访问 Get 请求。
这样每次改动都需要直接修改拦截器的代码,代码的拓展性就不高,如果可以定义一个接口,传入当前的 token,所有的校验规则都实现这个接口并进行自己的校验,拦截器通过注入或其他方式获取所有的校验类,挨个进行校验并返回:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public interface Rule {validate (UserToken token, Request request) ;public class TimeOutRule implements Rule {validate (UserToken token, Request request) {public class AdminRule implements Rule {validate (UserToken token, Request request) {
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 @Component @Slf4j public class AuthenticationInterceptor implements HandlerInterceptor {@AutoWired private List<Rule> rules;@Override public boolean preHandle (HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {if (handler.getClass().isAssignableFrom(HandlerMethod.class)) {if (isExclusion(handler)) {return true ;String token = request.getHeader("Authorization" );if (StringUtils.isBlank(token)) {"access_token" );if (StringUtils.isBlank(token)) {return false ;for (Rule rule : rules) {return true ;
再以后新增新的告警规则时,只需要添加新的 Rule 即可,不用修改原有的代码逻辑,而如果直接修改原有的代码,一方面需要进行逻辑的修改,测试需要全面,另一方面如果随着需求的变化不再校验了不方便删除。
相应的,为了支撑这样的拓展性,代码的可读性也变差了一些,理解起来也有了一些难度。
因此,在实际开发过程中,如果函数中的逻辑并不复杂,if 语句并没有很多,那么直接在函数中修改才是比较合理的选择。
里式替换 Liskov Substitution Principle:Functions that use pointers of references to base classes must be able to use objects of derived classes without knowing it。翻译一下就是:子类对象(object of subtype/derived class)能够替换程序(program)中父类对象(object of base/parent class)出现的任何地方,并且保证原来程序的逻辑行为(behavior)不变及正确性不被破坏。
如果熟悉多态的话,其实会觉得这很容易理解,因为父类引用可以指向子类对象,而子类继承了父类的方法,因此即使替换代码依然可以正常运行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class ParentFly {public Boolean fly () {return false ;public class SonFly extends ParentFly {public class Test {public void test (ParentFly parentFly) {public static void main (String[] args) {Test test = new Test ();new SonFly ());
上述例子中 SonFly 完全可以作为 ParentFly 类型的参数,并且程序不受影响
但是里式替换并不是多态,如果子类重写了父类的 fly 方法:
1 2 3 4 5 public class SonFly extends ParentFly {public Boolean fly () {return null ;
在父类的逻辑里,返回 true/false ,而子类重写了这个方法并返回 null,完全有可能导致使用该方法的位置出现空指针异常,这种有违背了 LSP 原则。
多态是面向对象编程的一大特性,也是面向对象编程语言的一种语法。它是一种代码实现的思路。而里式替换是一种设计原则,是用来指导继承关系中子类该如何设计的,子类的设计要保证在替换父类的时候,不改变原有程序的逻辑以及不破坏原有程序的正确性。
以下这些行为都不符合里式替换的原则:
子类违背父类声明要实现的功能;
子类违背父类对输入、输出、异常的约定。如找不到一个元素是返回 null,子类抛出了异常。
接口隔离 Interface Segregation Principle:Clients should not be forced to depend upon interfaces that they do not use。翻译一下就是:客户端不应该强迫依赖它不需要的接口。
例如现在有一个用户接口,里面包含很多功能:
1 2 3 4 5 6 7 8 9 10 public interface UserService {boolean register (String cellphone, String password) ;boolean login (String cellphone, String password) ;getUserInfoById (long id) ;getUserInfoByCellphone (String cellphone) ;public class UserServiceImpl implements UserService {
现在需要一个删除功能,但是删除功能只允许被某个模块调用,如果简单的在 UserService 中新增一个删除接口,那么所有注入 UserService 的地方都可以调用,一方面缺少足够的安全性,另一方面其他模块注入的 UserService 并不需要这个功能,因此最佳实践应该是定义一个新的 Service,并让 UserServiceImpl 实现这个接口:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public interface UserService {boolean register (String cellphone, String password) ;boolean login (String cellphone, String password) ;getUserInfoById (long id) ;getUserInfoByCellphone (String cellphone) ;public interface RestrictedUserService {boolean deleteUserByCellphone (String cellphone) ;boolean deleteUserById (long id) ;public class UserServiceImpl implements UserService , RestrictedUserService {
如果这不是一组接口,而是一个单独的类中的方法,例如示例计算一个集合中的最大值、最小值、平均值等
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class Statistics {private Long max;private Long min;private Long average;private Long sum;private Long percentile99;private Long percentile999;public Statistics count (Collection<Long> dataSet) {Statistics statistics = new Statistics ();return statistics;
如果调用该方法只是为了其中的 max 和 min,那么这个方法就该拆分,获取每个值单独一个方法;而如果所有的值都需要被展示,那么这个方法就是合适的。
现在假如有三个配置类:MysqlConfig、RedisConfig、KafkaConfig,希望其中 Redis 和 Kafka 支持功能 A,Mysql、Redis 支持功能 B,一种实现方式就是定义一个全的接口,包含 A 和 B,所有的 Config 都实现这个接口;另一种方式就是定义两个接口,不同的 Config 按需实现。
第二种方式无疑是更好的,一方面它符合单一职责的设计,另一方面它不违背接口隔离,不要求强制被实现,而且具有良好的拓展性。
某种程度上讲:单一职责原则和接口隔离原则有些相似,但接口隔离侧重于接口的设计,并从调用者是否只使用部分接口或接口的部分功能的角度来判断职责是否单一。
依赖反转 Dependency Inversion Principle,理解依赖反转首先要理解控制反转(Inversion Of Control),即 IOC:
1 2 3 4 5 6 7 8 9 10 11 12 13 public class UserServiceTest {public static boolean doTest () {public static void main (String[] args) {if (doTest()) {"Test succeed." );else {"Test failed." );
上述的示例代码中,需要我们完全控制流程的流转,而利用模板设计模式可以改变这一方式,如下代码所示,如果能在JunitApplication 启动前把所有的 TestCase 实例(其实是子类,因为这是抽象类)填充到 testCases 中即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public abstract class TestCase {public void run () {if (doTest()) {"Test succeed." );else {"Test failed." );public abstract void doTest () ;public class JunitApplication {private static final List<TestCase> testCases = new ArrayList <>();public static void register (TestCase testCase) {public static final void main (String[] args) {for (TestCase case : testCases) {case .run();
1 2 3 4 5 6 7 8 9 public class UserServiceTest extends TestCase {@Override public boolean doTest () {new UserServiceTest ();
在上面的示例中,这个抽象类就是框架提供的拓展点,我们只需要在这个拓展点上添加跟自己业务相关的代码,程序的执行就可以通过框架来控制,控制权从开发者“反转”到了框架。
事实上,实现控制反转的方法很多,除了上面的利用模板设计模式的方法之外,还可以利用大名鼎鼎的依赖注入。所以控制反转并不是一种具体的实现技巧,而是一种设计思想,一般用来指导框架层面的设计。
而依赖注入跟控制反转恰恰相反,它是一种具体的编码技巧。概括来说就是:不通过 new() 的方式在类内部创建依赖类对象,而是将依赖的类对象在外部创建好后,通过构造函数、函数参数等方式传递(或注入)给类使用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class Notification {private MessageSender messageSender;public Notification (MessageSender messageSender) {this .messageSender = messageSender;public void sendMessage (String cellphone, String message) {this .messageSender.send(cellphone, message);public interface MessageSender {void send (String cellphone, String message) ;public class SmsSender implements MessageSender {@Override public void send (String cellphone, String message) {public class InboxSender implements MessageSender {@Override public void send (String cellphone, String message) {MessageSender messageSender = new SmsSender ();Notification notification = new Notification (messageSender);
例如在上述示例代码的 30 行,先创建出具体的 Sender,31 行再通过构造器传入。
但是如果一个类需要很多的依赖类对象,类对象的创建和依赖注入会变得非常复杂。人工创建不但繁琐,还需要判断创建的顺序,容易出错且开发成本高,于是有了相应的框架,及“依赖注入框架”。我们只需要通过框架提高的拓展点,配置一下所有要创建的类对象和相互的依赖关系,就可以由框架来实现自动创建对象,管理对象的生命周期,依赖注入等功能。
现成的依赖注入框架有很多,比如 Google Guice、Java Spring、Pico Container、Butterfly Container 等。不过,如果你熟悉 Java Spring 框架,你可能会说,Spring 框架自己声称是控制反转容器 (Inversion Of Control Container),控制反转是一个宽泛的概念,而依赖注入框架则更具体一些。
而依赖反转原则:High-level modules shouldn’t depend on low-level modules. Both modules should depend on abstractions. In addition, abstractions shouldn’t depend on details. Details depend on abstractions。翻译一下大概意思就是:高层模块(high-level modules)不要依赖低层模块(low-level)。高层模块和低层模块应该通过抽象(abstractions)来互相依赖。除此之外,抽象(abstractions)不要依赖具体实现细节(details),具体实现细节(details)依赖抽象(abstractions)。
Tomcat 是运行 Java Web 应用程序的容器。我们编写的 Web 应用程序代码只需要部署在 Tomcat 容器下,便可以被 Tomcat 容器调用执行。按照之前的划分原则,Tomcat 就是高层模块,我们编写的 Web 应用程序代码就是低层模块。Tomcat 和应用程序代码之间并没有直接的依赖关系,两者都依赖同一个“抽象”,也就是 Sevlet 规范。Servlet 规范不依赖具体的 Tomcat 容器和应用程序的实现细节,而 Tomcat 容器和应用程序依赖 Servlet 规范。
KISS AND YAGNI KISS 即 Keep It Simple and Stupid,翻译一下就是保持简单。
有些公司会禁止使用多层 stream、lambda 表达式,原因就是这些虽然缩短了代码行数,但不容易被理解,尤其是stream 中嵌套 stream。因此并不是代码行数越少就越简单。包括正则表达式,使用多个简单易理解的正则会比使用一个大而全的正则更加易于理解,也更加简单和易于维护。
但对于一些复杂的问题,如 KMP 匹配子串,或者是一些对性能要求很高的场景,这类本身具有逻辑复杂、实现难度大的场景,使用复杂的方法来解决,也并不违背 KISS 原则。
YAGNI 原则的英文全称是:You Ain’t Gonna Need It。直译就是:你不会需要它。
在软件开发的过程中,一定不要过度设计,虽然要预留拓展点,但没必要提前编写这部分的代码。例如 Java 开发为了避免缺少依赖,提前往项目里引入大量常用的依赖包,这样的做法也是违背 YAGNI 的。
KISS 原则强调“如何做”的问题(尽量保持简单),而 YAGNI 原则说的是“要不要做”的问题。
指导原则:
不要使用同事很多不懂的技术,至少现阶段不要使用。例如虽然 Optional 语法出来很久了,但有些同事不太熟悉,导致对一些代码不太理解。
不要重复造轮子,要善于利用已有的工具类库。
不要过度优化。
DRY Don’t Repeat Yourself. 翻译一下就是不要重复你自己,即不要编写重复的代码。
这里最常遇到的其实不是完全相同的代码,一般这种 IDEA 也会给出提示。最常遇到的其实是多个同事一起开发,各自写了同样功能但是不同命名且不同实现的函数,例如同事A使用正则进行校验,同事B定制编码校验。这样会有一些问题:一方面如何后期逻辑变化,两个函数的实现都需要修改;另一方面,对于新入手项目的同事也不友好,不清楚为什么有的地方校验调用 A 函数,而有些地方调用 B 函数。
有些情况下某些校验可能被执行了两次,例如 controller 接口有一个根据 email 查找用户的功能
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class UserControleler {private UserServiceImpl service; public User getUserByEmail (String email) {if (StringUtils.isBlank(email)) {throw new IllegalArgumentException ("邮箱不能为空" );return service.getUserByEmail(email);public class UserServiceImpl {private UserDao userDao; public User getUserByEmail (String email) {if (StringUtils.isBlank(email)) {throw new IllegalArgumentException ("邮箱不能为空" );return userDao.findByEmail(email);
判断 email 输入是否为空的校验做了两次,实际上是完全没有必要的。这个例子没有涉及到数据库IO,所以对性能影响并不会很大,但是如果设计数据库查询执行了多次,就可能影响性能了。
DRY 原则从定义上与代码的复用有点类似,但它只是一个指导原则,复用是一种行为,而可复用性是对代码的一种评价,不重复和可复用完全是两个概念。
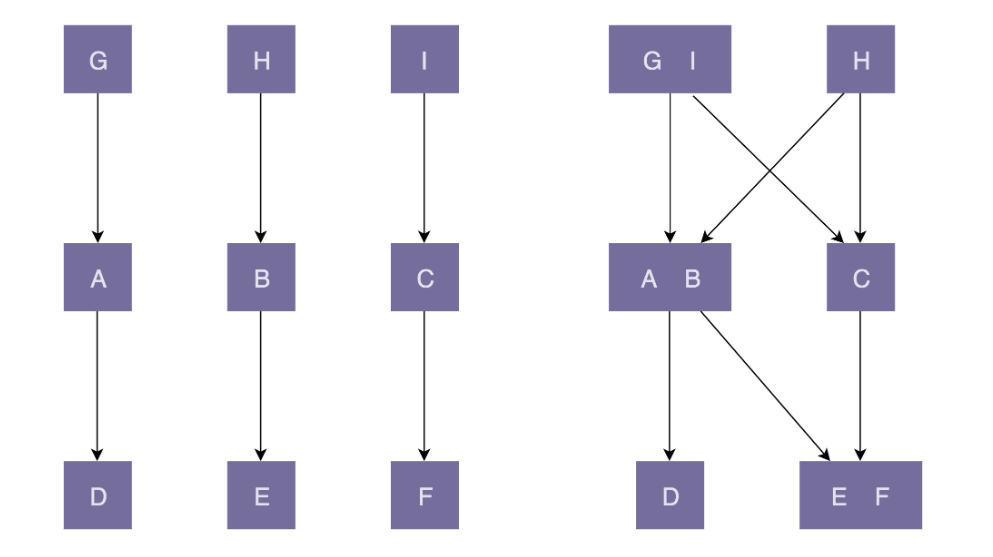
迪米特法则 迪米特法则的英文翻译是:Law of Demeter,缩写是 LOD,最原汁原味的翻译其实是:每个模块(unit)只应该了解那些与它关系密切的模块的有限知识)。或者说,每个模块只和自己的朋友“说话”(talk),不和陌生人“说话”(talk)。常用来指导设计出“高内聚,低耦合”的系统。
如上图所示,左侧的系统就是高内聚低耦合的,每个模块都只与相邻的模块进行交互,而右侧就不满足这样的情况,如果AB中的代码修改,会同时影响 GI 和H 模块。
例如有一个序列化和反序列化接口,如果有的类只想依赖序列化接口,另一部分类只想依赖反序列化接口
1 2 3 4 5 6 7 8 9 public class Serializer { public String serialize (Object object) { public String serializeMap (Map map) { public String serializeList (List list) { public Object deserialize (String objectString) { public Map deserializeMap (String mapString) { public List deserializeList (String listString) {
那么就可以定义两个接口 serialize 和 deserialize
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public interface Serializer {serialize (Object object) { serializeMap (Map map) { serializeList (List list) { public interface deserialize {deserialize (String objectString) { deserializeMap (String mapString) { deserializeList (String listString) { public class DemoClass_1 {private Serializable serializer;public Demo (Serializable serializer) {this .serializer = serializer;public class DemoClass_2 {private Deserializable deserializer;public Demo (Deserializable deserializer) {this .deserializer = deserializer;
这样就可以满足 DemoClass_1 对反序列化接口无感知,而 DemoClass_2 对序列化接口无感知的要求,既符合迪米特法则所说的 “依赖有限接口”,又体现了 “基于接口编程而非实现编程” 的设计原则。