Redis长什么样
Redis长什么样
我们都知道 Redis 是一个 <key,value> 的键值数据库,也就是一个 Map。我们平时是怎么实现这样一个 Map 的呢?
用数组,当一个 key 来的时候,首先进行 hash 运算,接着对数据的 length 取余,把这个键值对放在对应位置,这样能以 O(1) 的时间复杂度进行某个 key 的定位。
Redis 对外暴露了五种常见的数据结构,string、list、hash、set、sorted set;从内部实现的角度,则是 dict、sds、ziplist、quicklist、skiplist,Redis 通过这几种内部实现,组成了对外暴露的数据结构,充分的考虑了内存占用和操作速度。
本篇暂且介绍 Redis 的整体样貌,与数据结构相关的后续再补。
设计与分析
我们来看一下 Redis 的设计:
redisDb就是我们说的数据库,redis 有16个这样的数据库,其中的 dict *dict 是我们数据存放的字段
1 | |
- 前几个字段的类型都是 dict,分别是正常的键值对,设置了过期时间的键值对,客户端正在阻塞等待的键值对,已经有数据、可以唤醒阻塞客户端的键值对和被 redis 事务监控的键值对;
- id 字段取值为 0~15,也就是 redis 的数据库编号;
- 记录这个数据库中所有带过期时间键值对的平均剩余存活时间;
- 等待主动碎片整理的键列表,当开启主动碎片整理时,把需要整理的 key 放进这个链,逐个整理避免卡顿。
再看一下 dict 结构体的设计:
1 | |
dictType *type里有一堆函数指针,当有 key 来时,需要通过函数指针里的 hash 函数求 hash 值,对数组长度取余后还要调用比较函数判断对应位置的 key 与当前 key 是否相等(原因是会有 hash 冲突,redis 首先使用链表法解决冲突,头插法);void *privdata是私有数据指针,由调用者在创建dict的时候传进来;dictht ht[2],一般情况下 ht[1] 都是指向 NULL,只有在 rehash 的时候才有值。Redis 使用两个数组,当需要扩容时,读请求首先从 ht[0] 读,没有的话再去 ht[1],写请求直接写 ht[1],更新请求会略微复杂些;rehashidx,rehash 的索引,如果是-1,代表此时没有进行 rehash,否则代表需要进行迁移的数组下标。
再看一下dictht结构体的设计,ht,即 hashtable,学 java 的应该很熟悉
1 | |
dictEntry **table:一个 dictEntry 指针数组。key的哈希值最终映射到这个数组的某个位置上(对应一个bucket)。如果多个 key 映射到同一个位置,就发生了冲突,那么就拉出一个 dictEntry 链表;size:标识 dictEntry 指针数组的长度。它总是 2 的幂;sizemask:key 的 hash 值对 size 取模的结果其实等于 hash 值 & (size - 1),而且%运算会一直除,而&运算一次到位;used:记录dict中现有的数据个数。它与size的比值就是装载因子(load factor)。这个比值越大,哈希值冲突概率越高。
最终的数据是在 dictEntry 中,一起来看下:
1 | |
一个 key 的指针,一个联合类型,由于 hash 函数可能会冲突,所以还有 next 指针用来解决冲突(链表头插法):
- key 总是指向一个 sds 结构,也就是键值对的键;
- value 是一个联合类型,当值可以直接存储时(int、long、double)就直接存值,否则使用指针指向一个 robj 结构。
图示
Redis 整体结构的分析还是比较简单的,经过上述分析,我们可以得到这样的一个 Redis 结构图:
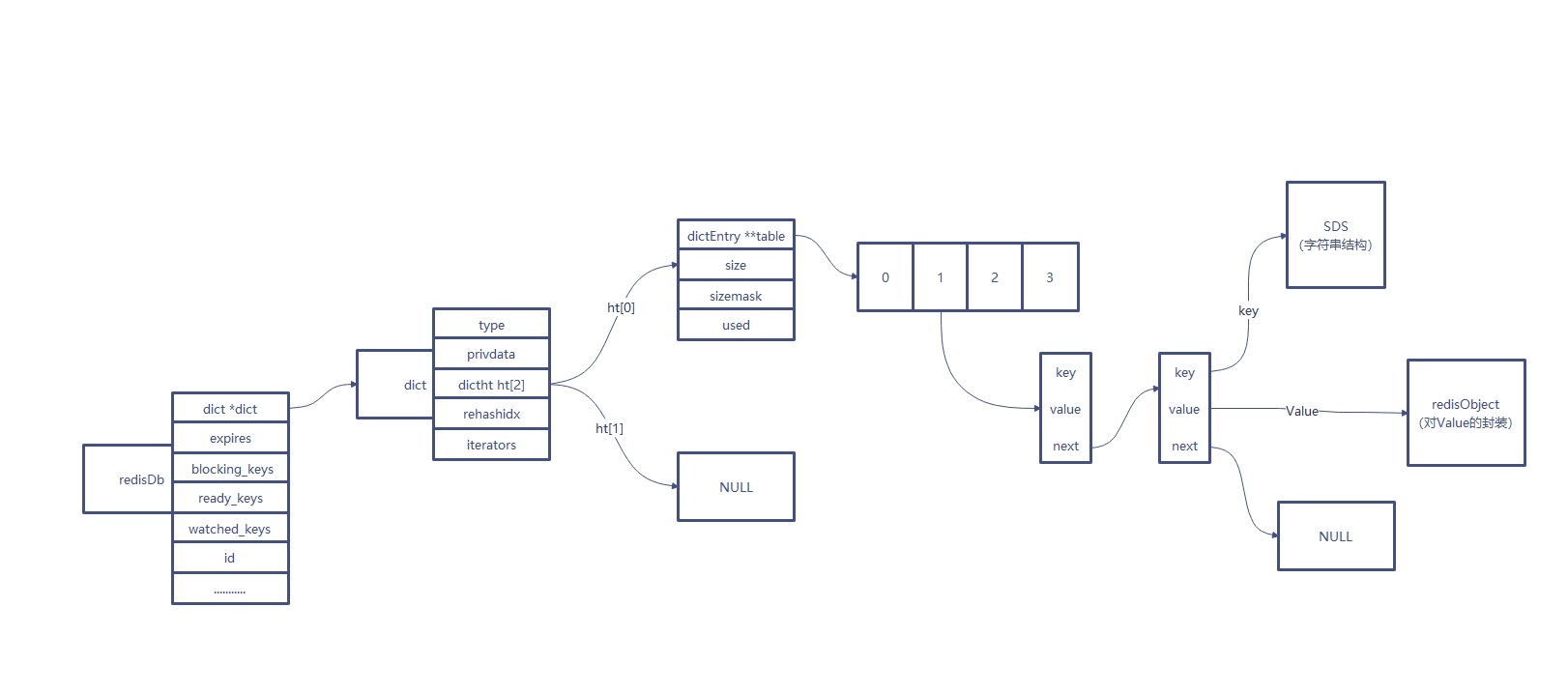
关于 Redis 的 dict、sds、ziplist、quicklist、skiplist 核心结构,以及涉及到的渐进式哈希在后续介绍~
Redis长什么样
https://zhuwenjie0716.github.io/2026/05/08/Redis长什么样/