Netty的ByteBuf好用在哪
Netty的ByteBuf好用在哪
ByteBuf 是 Netty 的数据容器,所有网络通信中字节流的传输都是通过 ByteBuf 完成的。很多开发者已经使用 ByteBuf 代替 ByteBuffer,即便并不是在写一个网络应用,也会单独使用 ByteBuf。
相比 JDK 的 ByteBuffer,Netty 的 ByteBuf 好在哪?
ByteBuffer
JDK 的 ByteBuffer 结构如下:
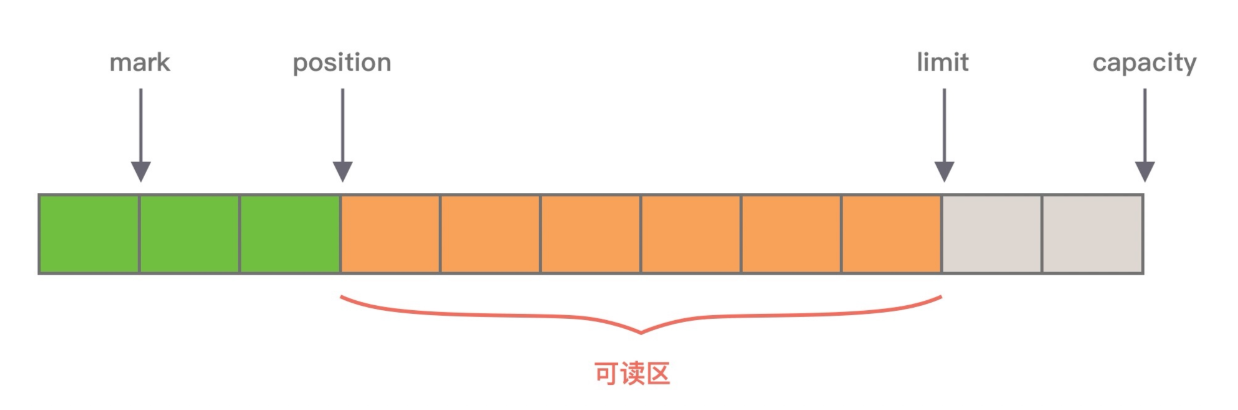
从图中可知, ByteBuffer 包含以下四个基本属性:
- mark:为某个读取过的关键位置做标记,方便回退到该位置;
- position:当前读取的位置;
- limit: buffer 中有效的数据长度大小;
- capacity:初始化时的空间容量。
从属性中也可以看出 ByteBuffer 的一些缺点:
- 容量在创建时指定,无法进行动态扩容,很难控制需要分配多大的容量;
- 读写操作都用 position 指针,需要频繁调用 flip、 rewind 方法切换读写状态。
接下来以 ByteBuffer 处理粘包写一段示例代码:
1 | |
代码中读之前需要先 ByteBuffer.flip() 切换读模式,ByteBuffer.mark() 标记,如果解析失败,需要 ByteBuffer.reset() 回滚位置,ByteBuffer.compact() 移动未读数据到头部,position 位置到未读数据之后,
ByteBuf
Netty 实现了一个性能更高、易用性更强的 ByteBuf,其结构如下:
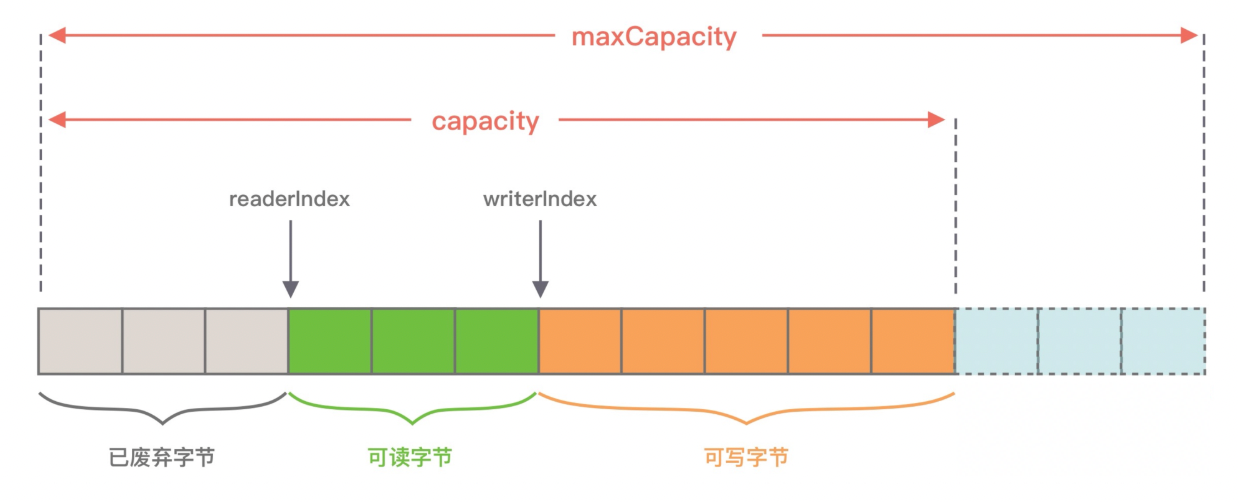
从图中可以看出, ByteBuf 包含三个指针: 读指针 readerIndex 、 写指针 writeIndex 、 最大容量 maxCapacity,根据指针的位置又可以将 ByteBuf 内部结构可以分为四个部分:
第一部分是 废弃字节,表示已经丢弃的无效字节数据。
第二部分是 可读字节,表示 ByteBuf 中可以被读取的字节内容,可以通过 writeIndex - readerIndex 计算得出。从 ByteBuf 读取 N 个字节, readerIndex 就会自增 N, readerIndex 不会大于 writeIndex,当 readerIndex == writeIndex 时,表示 ByteBuf 已经不可读。
第三部分是 可写字节,向 ByteBuf 中写入数据都会存储到可写字节区域。向 ByteBuf 写入 N 字节数据, writeIndex 就会自增 N,当 writeIndex 超过 capacity,表示 ByteBuf 容量不足,需要扩容。
第四部分是 可扩容字节,表示 ByteBuf 最多还可以扩容多少字节,当 writeIndex 超过 capacity 时,会触发 ByteBuf 扩容,最多扩容到 maxCapacity 为止,超过 maxCapacity 再写入就会出错。
Netty 重新设计的 ByteBuf 有效地区分了可读、可写以及可扩容数据,解决了 ByteBuffer 无法扩容以及读写模式切换烦琐的缺陷。
接下来以 ByteBuf 处理粘包写一段示例代码:
1 | |
相比 ByteBuffer,ByteBuf 不再需要繁琐的 flip、compact 操作,而且提供了 read/get, write/set 的数据读写 API,区别就是 get/set 不会移动 readIndex 和 writeIndex。
分类
ByteBuf 有多种实现类,每种都有不同的特性,下图是 ByteBuf 的家族图谱,可以划分为三个不同的维度: Heap/Direct 、 Pooled/Unpooled 和 Unsafe/非 Unsafe,我逐一介绍这三个维度的不同特性。
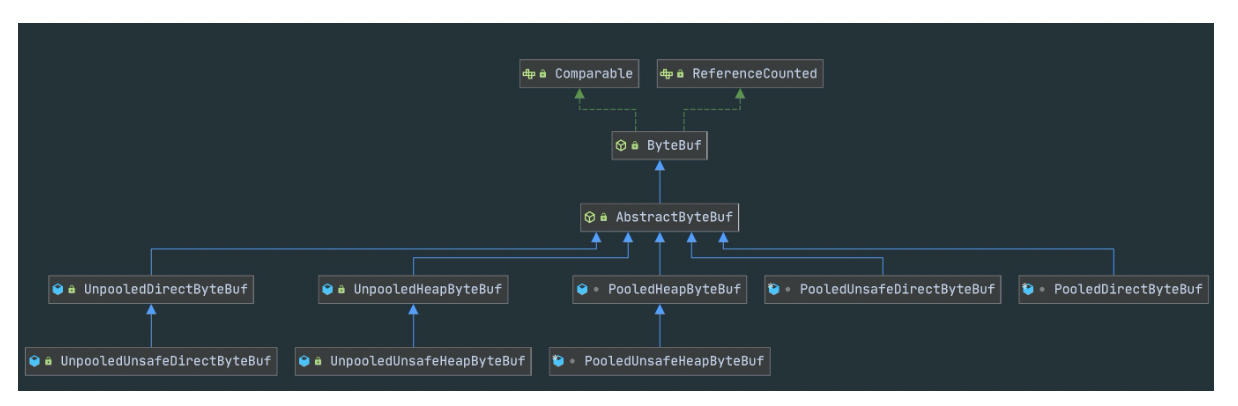
- Heap/Direct 就是堆内和堆外内存。 Heap 指的是在 JVM 堆内分配,底层依赖的是字节数据; Direct 则是堆外内存,不受 JVM 限制,分配方式依赖 JDK 底层的 ByteBuffer。
- Pooled/Unpooled 表示池化还是非池化内存。 Pooled 是从预先分配好的内存中取出,使用完可以放回 ByteBuf 内存池,等待下一次分配。而 Unpooled 是直接调用系统 API 去申请内存,确保能够被 JVM GC 管理回收。
- Unsafe/非 Unsafe 的区别在于操作方式是否安全。 Unsafe 表示每次调用 JDK 的 Unsafe 对象操作物理内存,依赖 offset + index 的方式操作数据。非 Unsafe 则不需要依赖 JDK 的 Unsafe 对象,直接通过数组下标的方式操作数据。
这些涉及到 Netty 如何高效的使用内存,未来有时间会单独介绍。
引用计数
ByteBuf 中还有一个重要的概念:引用计数,用来管理 ByteBuf 的生命周期,特别是池化内存的自动回收,防止内存泄漏。
当新创建一个 ByteBuf 对象时,它的初始引用计数为 1 ,当 ByteBuf 调用 release() 后,引用计数减 1。
引用计数对于 Netty 设计缓存池化有非常大的帮助,当引用计数为 0 ,该 ByteBuf 可以被放入到对象池中,避免每次使用 ByteBuf 都重复创建,对于实现高性能的内存管理有着很大的意义。
所以在写 InboundHandler 时,推荐直接继承 SimpleChannelInboundHandler,它在 channelRead0 方法执行后会自动帮我们处理释放
1 | |
小结
Netty 提供的数据容器 ByteBuf,不仅解决了 JDK NIO 中 ByteBuffer 的缺陷,而且提供了易用性更强的接口,相比于 ByteBuffer 它提供了很多非常酷的特性:
- 容量可以按需动态扩展,类似于 StringBuffer;
- 读写采用了不同的指针,读写模式可以随意切换,不需要调用 flip 方法;
- 通过内置的复合缓冲类型可以实现零拷贝(CompositeByteBuf);
- 支持引用计数;
- 支持缓存池。