Netty如何处理半包&粘包
TCP 传输协议是面向流的,没有数据包界限。当程序要发送一个较大的包时,由于滑动窗口以及 MTU 的影响,有可能会拆分为多个包传输;当程序要发送较小的包时,为了提高通信效率,Linux 的 Nagle 算法可能会将多个报文合并成一个大的报文进行发送。
MTU(Maxitum Transmission Unit) 是链路层一次最大传输数据的大小。 MTU 一般来说大小为 1500 Byte。MSS(Maximum Segement Size) 是指 TCP 最大报文段长度,一般是 1460 Byte。滑动窗口则是用于流量控制,用于接收方反馈接受窗口大小,进而控制发送方发送速度。
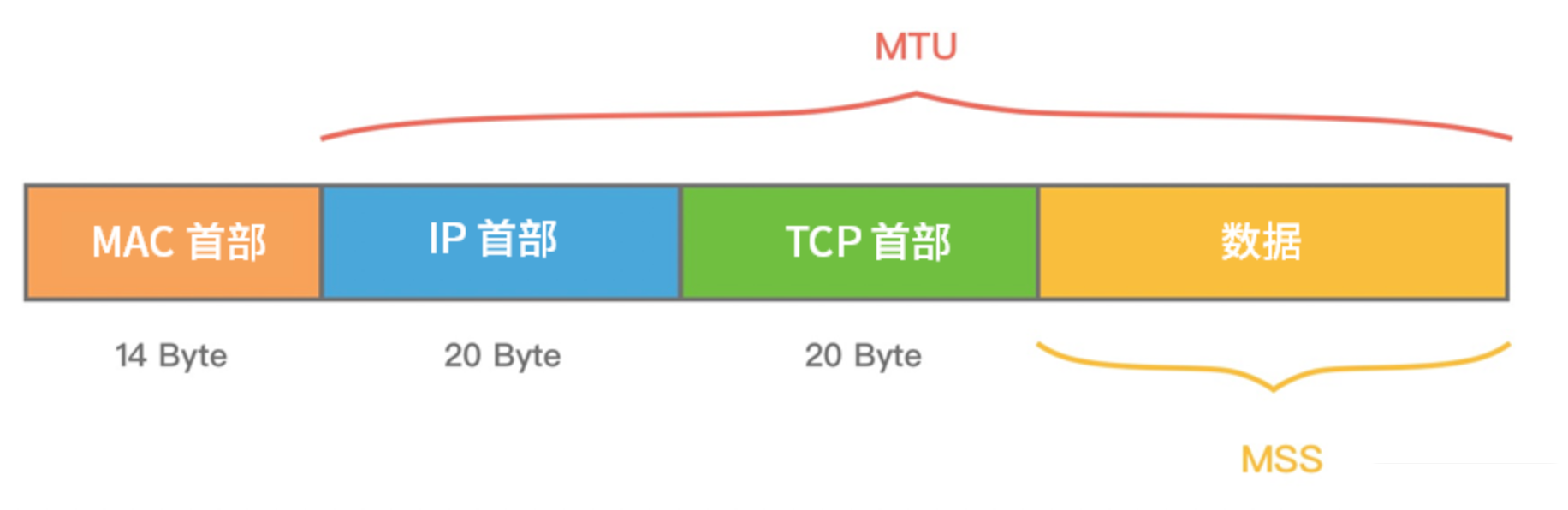
受这些因素,应用程序收到的字节流可能是不完整的(半包)也可能是粘在一起的(粘包),需要进行一定的操作才能得到想要的数据。也就是说,这个问题依赖自定义应用层通信协议解决。
一次解码
通常把找出消息的边界的过程称为“一次解码”。
固定长度法
双方约定,每次数据长度为 N 个 Byte,如果收到的数据长度不足则继续等待读取符,发送方的数据如果不足该长度则使用空位进行补齐,会造成一定的空间浪费。
该方法比较简单,但设定固定长度的值是个难题,如果长度太大会造成字节浪费,长度太小又会影响消息传输,所以在一般情况下不会被采用。
Netty: FixedLengthFrameDecoder。
特定分割符
发送方发送数据时在末尾追加特定分割符,接收方根据分隔符进行消息拆分。
该方法也比较简单,常见的做法是将消息进行编码(如:base64),再选择以外的字符作为分割符,否则需要扫描消息内容,对内容中与分割符相同的符号进行转义处理。
Netty: DelimiterBasedFrameDecoder。
固定字段存长度
在消息的最前方固定字段(如:4B)存这个消息的长度值,接着向后读取该值个长度的字节数据。
1
2
3
4
| 消息头 消息体
+--------+----------+
| Length | Content |
+--------+----------+
|
这是项目开发中最常用的一种协议,既能精准定位数据,内容也不需要转义。
Netty: LengthFieldBasedFrameDecoder。
二次解码
“一次解码”获得了想要的消息(字节),还需要进行“二次解码”转为程序中需要的对象,其实也是我们平时说的反序列化。
反序列化与序列化是相对的,一般需要在性能、可读性中做权衡,这也是实现 RPC 需要考虑的,常见的方式有:Java 序列化、xml、json、protobuf 等,可以参考:选择合适的RPC。
自定义通信协议实践
接下来以客户端向服务端发送认证操作为例进行实践,按照这个方案,即使未来增加新的操作类型,也只需要新建对应的操作类和操作结果类,并在枚举类中新增对应操作即可。
交互消息体设计
我们采用“固定长度存字段”法进行一次解码。在消息最前方加2字节标识消息长度,并定义消息由 header 和 body 组成。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
|
@Data
public abstract class Message<T extends MessageBody> {
private MessageHeader messageHeader;
private T messageBody;
public void encode(ByteBuf byteBuf) {
byteBuf.writeInt(messageHeader.getVersion());
byteBuf.writeLong(messageHeader.getStreamId());
byteBuf.writeInt(messageHeader.getOpCode());
byteBuf.writeBytes(JsonUtil.toJson(messageBody).getBytes());
}
public abstract Class<T> getMessageBodyDecodeClass(int opcode);
public void decode(ByteBuf msg) {
int version = msg.readInt();
long streamId = msg.readLong();
int opCode = msg.readInt();
MessageHeader messageHeader = new MessageHeader();
messageHeader.setVersion(version);
messageHeader.setOpCode(opCode);
messageHeader.setStreamId(streamId);
Class<T> bodyClazz = getMessageBodyDecodeClass(opCode);
T body = JsonUtil.fromJson(msg.toString(StandardCharsets.UTF_8), bodyClazz);
this.messageHeader = messageHeader;
this.messageBody = body;
}
}
|
MessageHeader 中的内容由业务定义,可以自行拓展,但记得修改上述 Message 类的 encode 和 decode 方法。
1
2
3
4
5
6
7
8
9
| @Data
public class MessageHeader {
private int version = 1;
private int opCode;
private long streamId;
}
|
1
2
3
| public abstract class MessageBody {
}
|
MessageBody 即消息体可以分为两大类,一类是操作(Operation),一类是操作结果(OperationResult)。
1
2
3
4
5
6
| public abstract class Operation extends MessageBody {
public abstract OperationResult execute();
}
|
1
2
3
| public abstract class OperationResult extends MessageBody {
}
|
操作类消息即为请求(RequestMessage),操作结果类消息即为响应(ResponseMessage)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| public class RequestMessage extends Message<Operation> {
@Override
public Class getMessageBodyDecodeClass(int opcode) {
return OperationType.fromOpCode(opcode).getOperationClazz();
}
public RequestMessage(Long streamId, Operation operation) {
MessageHeader messageHeader = new MessageHeader();
messageHeader.setStreamId(streamId);
messageHeader.setOpCode(OperationType.fromOperation(operation).getOpCode());
this.setMessageHeader(messageHeader);
this.setMessageBody(operation);
}
}
|
1
2
3
4
5
6
7
8
9
| public class ResponseMessage extends Message<OperationResult> {
@Override
public Class getMessageBodyDecodeClass(int opcode) {
return OperationType.fromOpCode(opcode).getOperationResultClazz();
}
}
|
其中的 OperationType 为枚举类,定义了三元组(操作码、操作类、操作结果类)。
操作消息体设计
接下来以认证请求作为一种操作类型作为示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| @Data
public class AuthOperation extends Operation {
private final String userName;
private final String password;
@Override
public AuthOperationResult execute() {
if ("admin".equalsIgnoreCase(this.userName)) {
AuthOperationResult response = new AuthOperationResult(true);
return response;
}
return new AuthOperationResult(false);
}
}
|
1
2
3
4
5
6
| @Data
public class AuthOperationResult extends OperationResult {
private final boolean passAuth;
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| @Getter
public enum OperationType {
AUTH(1, AuthOperation.class, AuthOperationResult.class);
private final int opCode;
private final Class<? extends Operation> operationClazz;
private final Class<? extends OperationResult> operationResultClazz;
OperationType(int opCode, Class<? extends Operation> operationClazz, Class<? extends OperationResult> responseClass) {
this.opCode = opCode;
this.operationClazz = operationClazz;
this.operationResultClazz = responseClass;
}
public static OperationType fromOpCode(int type) {
return getOperationType(requestType -> requestType.opCode == type);
}
public static OperationType fromOperation(Operation operation) {
return getOperationType(requestType -> requestType.operationClazz == operation.getClass());
}
private static OperationType getOperationType(Predicate<OperationType> predicate) {
OperationType[] values = values();
for (OperationType operationType : values) {
if (predicate.test(operationType)) {
return operationType;
}
}
throw new AssertionError("no found type");
}
}
|
编解码设计
业务定义写好了,接下来是服务端的编解码器。
一次解码
定义最前方2字节长度为消息体长度,一次解码找到消息的边界,并把消息读取为 Bytebuf,构造器中第二三个参数分别是长度字段偏移量,长度字段长度:
1
2
3
4
5
| public class FrameDecoder extends LengthFieldBasedFrameDecoder {
public FrameDecoder() {
super(Integer.MAX_VALUE, 0, 2, 0, 2);
}
}
|
二次解码
经过“一次解码”,我们可以拿到一个消息对应的字节流(Bytebuf),由于这是服务端,所以收到的消息一定是 RequestMessage,“二次编码”将消息转为 RequestMessage 对象:
1
2
3
4
5
6
7
8
| public class ProtocolDecoder extends MessageToMessageDecoder<ByteBuf> {
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf byteBuf, List<Object> out) throws Exception {
RequestMessage requestMessage = new RequestMessage();
requestMessage.decode(byteBuf);
out.add(requestMessage);
}
}
|
业务处理
经过解码,此时已经拿到了对应的 RequestMessage,获取响应结果并写回客户端即可:
1
2
3
4
5
6
7
8
9
10
11
| public class ServerProcessHandler extends SimpleChannelInboundHandler<RequestMessage> {
@Override
protected void channelRead0(ChannelHandlerContext ctx, RequestMessage requestMessage) throws Exception {
Operation operation = requestMessage.getMessageBody();
OperationResult operationResult = operation.execute();
ResponseMessage responseMessage = new ResponseMessage();
responseMessage.setMessageHeader(requestMessage.getMessageHeader());
responseMessage.setMessageBody(operationResult);
ctx.writeAndFlush(responseMessage);
}
}
|
二次编码
业务处理流程中写出的是个 ResponseMessage 对象,需要进行序列化才能发送到网络中:
1
2
3
4
5
6
7
8
| public class ProtocolEncoder extends MessageToMessageEncoder<ResponseMessage> {
@Override
protected void encode(ChannelHandlerContext ctx, ResponseMessage responseMessage, List<Object> out) throws Exception {
ByteBuf buffer = ctx.alloc().buffer();
responseMessage.encode(buffer);
out.add(buffer);
}
}
|
一次编码
“二次编码”得到了消息的字节流数据(Bytebuf),需要在最前方新增2字节数据标识长度:
1
2
3
4
5
| public class FrameEncoder extends LengthFieldPrepender {
public FrameEncoder() {
super(2);
}
}
|
服务端
服务端代码中需要按照顺序组装起对应的编解码器及业务处理器。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| public class Server {
public static void main(String[] args) throws InterruptedException, ExecutionException {
NioEventLoopGroup bossGroup = new NioEventLoopGroup(1);
NioEventLoopGroup workGroup = new NioEventLoopGroup();
serverBootstrap.channel(NioServerSocketChannel.class);
serverBootstrap.handler(new LoggingHandler(LogLevel.INFO));
serverBootstrap.group(bossGroup, workGroup);
serverBootstrap.childHandler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
pipeline.addLast(new FrameDecoder());
pipeline.addLast(new FrameEncoder());
pipeline.addLast(new ProtocolEncoder());
pipeline.addLast(new ProtocolDecoder());
pipeline.addLast(new LoggingHandler(LogLevel.INFO));
pipeline.addLast(new ServerProcessHandler());
}
});
ChannelFuture channelFuture = serverBootstrap.bind(8090).sync();
channelFuture.channel().closeFuture().get();
}
}
|
小结
上述过程中,客户端发送来的请求会先经过一次解码器变为 Bytebuf,再经过二次解码器变为 RequestMessage,在业务处理中得到对应的响应并写回客户端,经二次编码器转为 Bytebuf,最后由一次编码器在最前方2字节增加消息体长度字段。
类图定义如下:
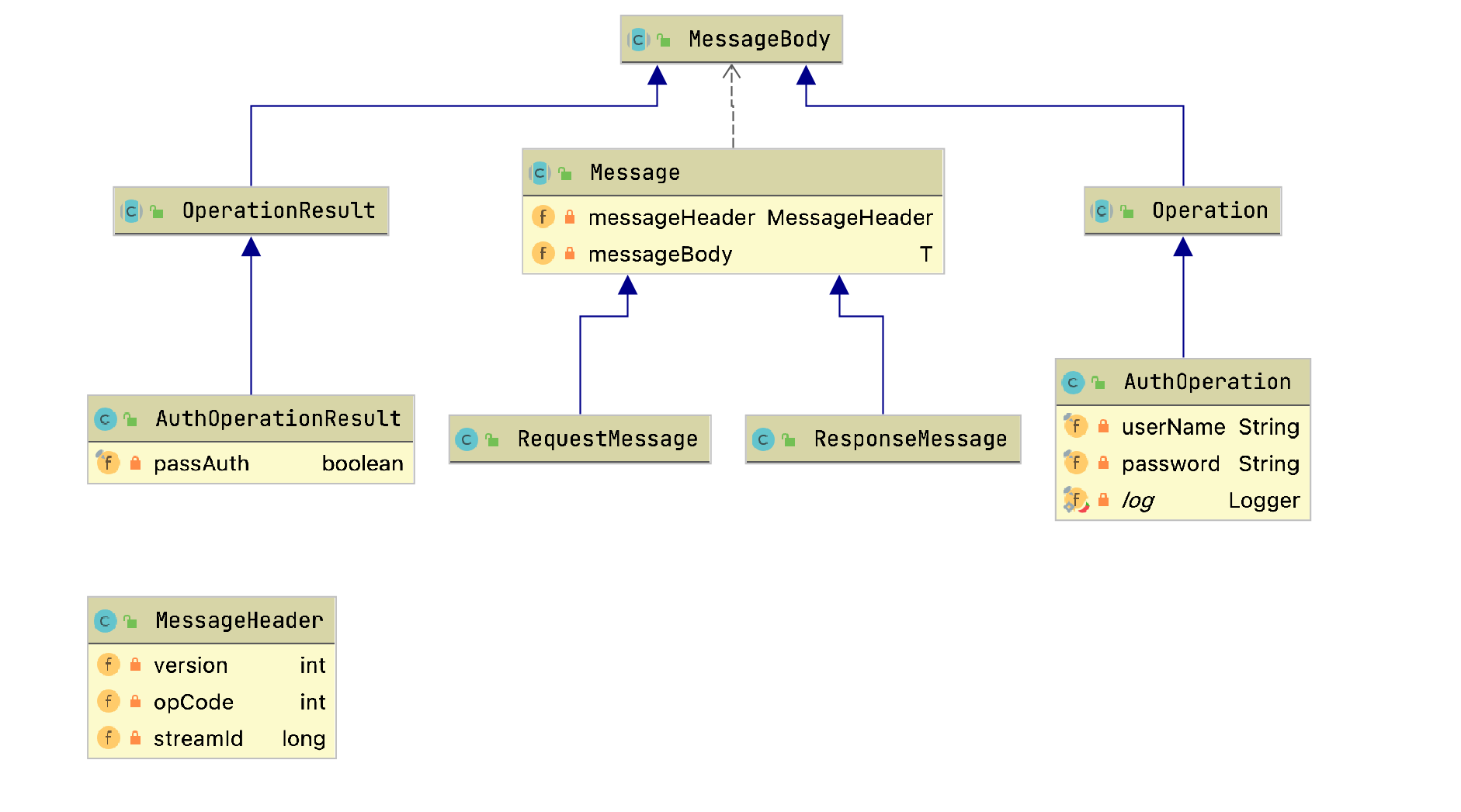
注:上述实践中仅包含了服务端代码,未包含客户端代码。
总结
为了处理 TCP 编程中粘包半包以及反序列化的问题,Netty 内置了一些常见的解码器,解码就是找到数据流边界并转为系统中对象的流程。
Netty 中提供了 ByteToMessageDecoder 和 MessageToMessageDecoder 类来进行解码操作。

相应的,选择了对应的解码器后也要编写对应的编码器代码。
同时,本文展示了一种关于自定义通信协议的实践。