分布式系统中的谁先谁后
分布式系统中的谁先谁后
情景描述
前端会定时的更新 redis 中用户的学习时长(增量而非累加值),后端有定时任务定时同步 redis 中的值到业务数据库中。后来为了提高后端性能,又在其他节点部署了一份服务,通过 nginx 做了负载均衡,但是忘了修改定时任务为 xxl-job 实现(即每个节点可能都会执行)。
思考这样的执行逻辑:
- 后端服务1从 redis 中得知需要修改用户学习时长为原始值 + 3
- 后端服务1从业务库中查询得到现在用户学习时长为 0,于是修改 PO 中该值为 3,在调用 dao.save(po) 前发生 gc
- redis 更新用户时长为 4
- 后端服务2从 redis 中得知需要修改用户学习时长为原始值 + 4
- 后端服务2从业务库中查询得到现在用户学习时长为 0,于是修改 PO 中该值为 4,调用 dao.save(po) 保存成功
- 后端服务1从 gc 中恢复,调用 dao.save(po) 保存值成功
此时数据库中的值是 3 而非 4,业务逻辑出现问题。这个问题并不是使用没有 gc 的语言就可以避免的,即使没有 gc、也可能会有网络延迟、主机缓冲区阻塞等情况。
如果给每次更新都带上一个绝对时间是否可行呢?在数据库服务收到后端服务1的更新请求时,发现服务2的更新请求更新时间晚于服务1,因此拒绝服务1的更新请求。
不过在自然界中,无论采用怎样的时间同步机制,服务器的时钟并不能时刻保持一致,而且这样的绝对时间精度总有上限的。两次数据变更,间隔时间可能非常小,比如就是来源于邻近两行代码的执行而已,这样的时间间隔,即便是最精密的物理时钟,可能都无法感知。
携带绝对时间的想法,源于我们想对系统中的事件进行全局的排序。
逻辑时钟
Lamport 在他的论文中提出了逻辑时钟的概念,我们为每个进程 𝑃𝑖 分别定义一个时钟 𝐶𝑖,它为进程中的任一事件 𝑎 分配一个值 𝐶𝑖 ⟨𝑎⟩。整个系统的时钟由函数 𝐶 表示,它为任一事件 𝑏 分配数值 𝐶⟨𝑏⟩,其中,若 𝑏 是进程 𝑃𝑗 中的一个事件,则 𝐶⟨𝑏⟩ = 𝐶𝑗 ⟨𝑏⟩。注意此时定义的时钟和物理时间毫无关系,可以认为这就是一个逻辑时钟。
接下来介绍一下事件的“先于发生”(由于没有物理时钟,不能再依靠绝对时间来判断)关系(此处有些像多线程中的 happened before):
定义:系统中事件集合上的关系“→”是满足以下三个条件的最小关系:
(1)若 𝑎 和 𝑏 是同一进程中的事件,且 𝑎 早于 𝑏 发生,则 𝑎 → 𝑏。
(2)若 𝑎 是一个进程的消息发送事件,𝑏 是另一进程接收同一消息的事件,则 𝑎 → 𝑏。
(3)若 𝑎 → 𝑏 且 𝑏 → 𝑐,则 𝑎 → 𝑐。
对两个不同的事件 𝑎 和 𝑏,若 𝑎 ↛ 𝑏 且 𝑏 ↛ 𝑎,则称 𝑎 和 𝑏 是并发的(concurrent)。 我们假设对任意事件 𝑎,𝑎 ↛ 𝑎(事件先于自身发生似乎没有实际意义)。这意味着 → 是系统中所有事件的集合上的反自反(irreflexive)的偏序关系。
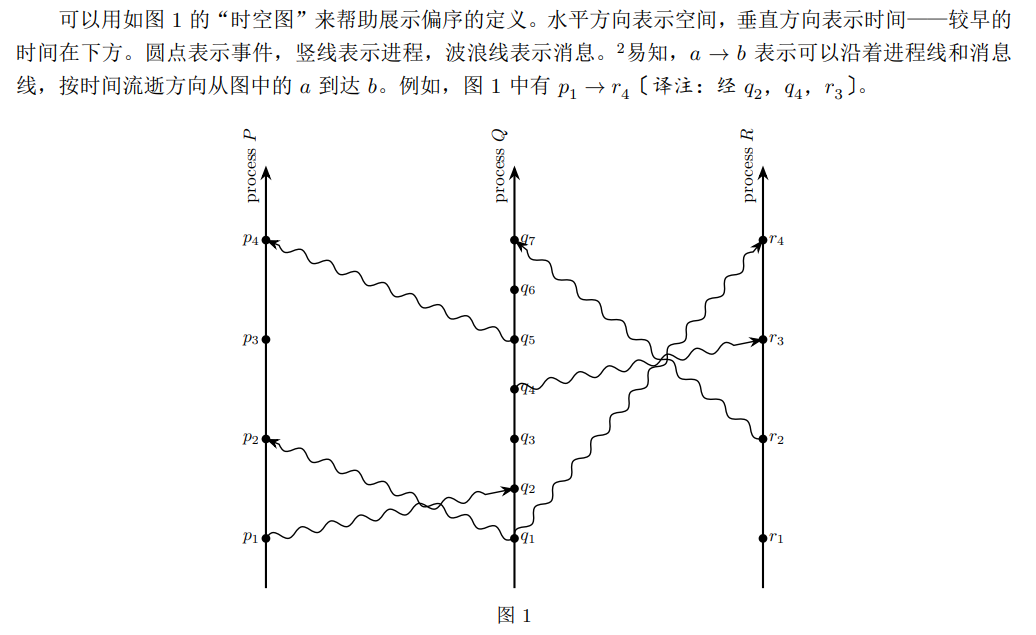
在这张图里 𝑝3 和 𝑞3 就是并发的,即使图中暗示了 𝑞3 发生的物理时间会更早(图中只能证明:𝑞1 → 𝑝2 → 𝑝3)。
我们希望事件满足这样的时钟条件:对于任意事件 𝑎,𝑏,若 𝑎 → 𝑏,则 𝐶⟨𝑎⟩ < 𝐶⟨𝑏⟩。注意它的逆命题并不成立, 𝐶⟨𝑎⟩ < 𝐶⟨𝑏⟩ 也可能二者可能不存在 → 关系而无法比较。
满足以下的条件也就满足了时钟条件:
- C1 若 𝑎 和 𝑏 都是进程 𝑃𝑖 中的事件,且 𝑎 先于 𝑏 发生,则 𝐶𝑖 ⟨𝑎⟩ < 𝐶𝑖 ⟨𝑏⟩。
- C2 若 𝑎 是进程 𝑃𝑖 发送消息的事件,𝑏 是进程 𝑃𝑗 接收到该消息的事件,则 𝐶𝑖 ⟨𝑎⟩ < 𝐶𝑗 ⟨𝑏⟩。
全序关系
为了保证时钟系统满足时钟条件,我们需确保其满足条件 C1 和 C2。条件 C1 很简单;进程仅需遵循以下的实现规则:
- IR1 每个进程 𝑃𝑖 在任意两个相继的事件之间增加 𝐶𝑖。
为了满足条件 C2,我们要求每个消息 𝑚 包含一个时间戳 𝑇𝑚,该时间戳等于发送消息的时刻。收到时间戳为 𝑇𝑚 消息后,进程必须推动其时钟,使其晚于 𝑇𝑚。更确切地说,我们有以下规则。
- IR2 (a) 若 𝑎 是进程 𝑃𝑖 发送消息 𝑚 这一事件,则消息 𝑚 需包含时间戳 𝑇𝑚 = 𝐶𝑖 ⟨𝑎⟩;
- IR2 (b) 一旦收到消息 𝑚,进程 𝑃𝑗 就将其时钟 𝐶𝑗 设置为不小于当前值,且大于 𝑇𝑚 的值。
这样可以满足偏序关系,但对于并发的事件 𝑎 和 𝑏 完全有可能 𝐶𝑖 ⟨𝑎⟩ = 𝐶𝑖 ⟨𝑏⟩,此时需要借助一个任意的全序关系来打破僵局,例如进程 id。更准确地说,我们定义关系 ⇒ 如下: 若 𝑎 是进程 𝑃𝑖 的事件,𝑏 是进程 𝑃𝑗 的事件,则 𝑎 ⇒ 𝑏 当且仅当
(i) 𝐶𝑖 ⟨𝑎⟩ < 𝐶𝑗 ⟨𝑏⟩ ;或(ii) 𝐶𝑖 ⟨𝑎⟩ = 𝐶𝑗 ⟨𝑏⟩ 且 𝑃𝑖 ≺ 𝑃𝑗。
≺ 为任意的全序关系,这定义了全序,且时钟条件意味着,若 𝑎 → 𝑏,则 𝑎 ⇒ 𝑏。
能将事件全局排序对实现分布系统是非常有用的。实际上,实现正确的逻辑时钟系统就是为了获得全序。
分布式互斥算法
文中基于此提供了一个分布式互斥算法,用于在多个进程之间安全地共享一个资源。在系统中有多个进程(例如 P1,P2,…,Pn),它们共享一个资源,满足以下条件:
- 同一时刻只能有一个进程使用该资源(条件1:互斥)
- 资源请求必须按照发出请求的先后顺序被满足(条件2)
- 只要每个获得资源的进程最终都会释放资源,那么每个请求最终都会被满足(条件3:无饥饿)
只看背景可能会认为这是一个分布式锁的问题,但分布式锁并不需要满足条件2,条件2要求系统能对并发请求也确定一个全局顺序。但分布式系统中,不同进程发出的请求可能没有直接的因果顺序(即并发的),因此需要人为构造一个全序。
算法依赖的机制
- 逻辑时钟:每个进程 Pi 维护一个逻辑时钟 Ci ,按照规则 IR1(事件间递增)和 IR2(消息携带时间戳,接收时调整)运行。由此得到所有事件的偏序 →,再通过比较 (Ci(a),进程ID) 扩展为全序 ⇒。
- 消息假设:
- 任意两个进程之间,消息按发送顺序被接收(FIFO 通道)。
- 消息最终都会被收到(无无限延迟或丢失)。
- 每个进程可以直接向其他所有进程发送消息。
算法的数据结构
每个进程 Pi 维护一个请求队列(本地,不与其他进程共享)。队列中存放形如 (T, P_j) 的消息,表示进程 Pj 在逻辑时间 T 发起的资源请求。初始时,队列中只有一条消息 (T0, P0),其中 P0 是初始拥有资源的进程,T0 小于所有时钟的初始值。
算法规则
规则中的每个动作都视为一个原子事件。
请求资源
当 Pi 需要资源时:- 生成当前逻辑时间戳 Tm=Ci。
- 向所有其他进程发送消息
"请求资源 (T_m, P_i)"。 - 同时将这条消息放入自己的请求队列。
接收请求消息
任何进程 Pj(包括 Pi 自己)收到"请求资源 (T_m, P_i)"后:- 将消息插入自己的请求队列(按 ⇒⇒ 全序排序,即先按时间戳,再按进程 ID)。
- 向 Pi 回复一个带时间戳的确认消息(确认的目的是让 Pi 知道对方已收到请求,规则 5 会用到)。
释放资源
当 Pi 使用完资源后:- 从自己的请求队列中删除
(T_m, P_i)这一条目(即自己的请求)。 - 向所有其他进程发送
"释放资源 (P_i)"消息。
- 从自己的请求队列中删除
接收释放消息
收到"释放资源 (P_i)"后,进程 Pj 从自己的请求队列中删除所有来自 Pi 的请求消息(即删除(T_m, P_i)条目)。获得资源
进程 Pi 持续检查以下两个条件是否同时满足:- (i) 自己的请求队列中,排在最前面(按全序 ⇒⇒ 最小)的消息就是它自己发出的
(T_m, P_i)。 - (ii) 它已经收到了所有其他进程发来的消息,且这些消息的时间戳都大于 Tm。
这里“所有其他进程发来的消息”是指:每个其他进程 Pj 都已经向 Pi 发送过一条时间戳大于 Tm的消息。实际上,这可以通过规则 2 中的确认消息来满足:只要 Pi 收到了来自 Pj 的确认,且该确认的时间戳 > Tm,就说明 Pj 已经知道了 Pi 的请求,并且其队列中任何比 Tm 更早的请求都已经在 Pi 之前处理了。
当这两个条件都成立时,Pi 就可以安全地获得资源。
- (i) 自己的请求队列中,排在最前面(按全序 ⇒⇒ 最小)的消息就是它自己发出的
算法为什么正确
- 条件 I(互斥):
如果两个进程同时认为自己获得了资源,那么它们各自的请求必定都排在各自队列的首位。但由于全序 ⇒⇒ 对所有进程的队列是一致的(因为所有进程都收到同样的请求消息,并按相同规则排序),因此全序中只能有一个最小请求。所以只有一个进程能同时满足条件 (i)。 - 条件 II(按请求顺序满足):
假设 Pa 的请求 Ra 在因果顺序上先于 Pb 的请求 Rb(即 Ra→Rb)。由于逻辑时钟满足 C(Ra)<C(Rb),因此 Ra 的全序一定小于 Rb,所以 Ra 会在所有队列中排在 Rb 前面,先获得资源。 - 条件 III(无饥饿):
对于任何请求 R,最终所有其他进程都会收到它(消息最终到达),并通过确认告知请求者。当排在 R 之前的所有请求都被释放后,R 就会成为队列首位,并且条件 (ii) 也会满足(因为所有进程都已经发送了大于 R 时间戳的确认),因此 R 最终会被授予。
算法的局限性与意义
- 通信开销大:每次请求和释放都需要向所有其他进程发送消息,复杂度 O(N),不适合大规模系统。
- 对故障敏感:如果某个进程崩溃,整个系统可能阻塞(因为没有收到它的确认或释放消息)。算法没有处理故障,需要额外的机制(如超时)。
- 历史地位:该算法是复制状态机(Replicated State Machine)思想的雏形。Lamport 后来明确指出,这篇论文的真正贡献是:通过给所有事件一个全局排序,可以将分布式系统建模为一个确定性状态机,每个进程独立重放相同的命令序列,从而实现任意分布式服务。互斥算法只是一个演示的例子。
简单的直观理解
可以把算法想象成“投票加排队”:
- 每个进程想用资源时,就向所有人广播“我想用,这是我的票号(时间戳)”。
- 每个人都把收到的请求按票号顺序放在自己的小本本上。
- 只有当一个人的票号排在最前面,并且确认了所有其他人都已经知道他的票号(即别人没有更早的未处理请求)时,他才能进门。
- 用完资源后,广播“我出来了”,所有人就把他的票号从小本本上划掉,下一个票号的人就能进去。
这个机制保证了全局唯一的顺序,从而解决了分布式互斥问题。